|
Violet Fu Yiwei Lyu Muhammad Khalifa Tiange Luo . Before joining UMich, I earned my M.S. in Artificial Intelligence from Seoul National University, where I had the privilege of being advised by Prof. Gunhee Kim in the Vision & Learning Laboratory. My research interests lie in multimodal agents and reinforcement learning, with the goal of building real-world agents. Currently, I am working on scalable methods for constructing datasets from videos to support the development of generalizable GUI agents. (Last updated on: Jan 10, 2026)
Email: yedasong __AT__ umich.edu / |

|
|
|
|
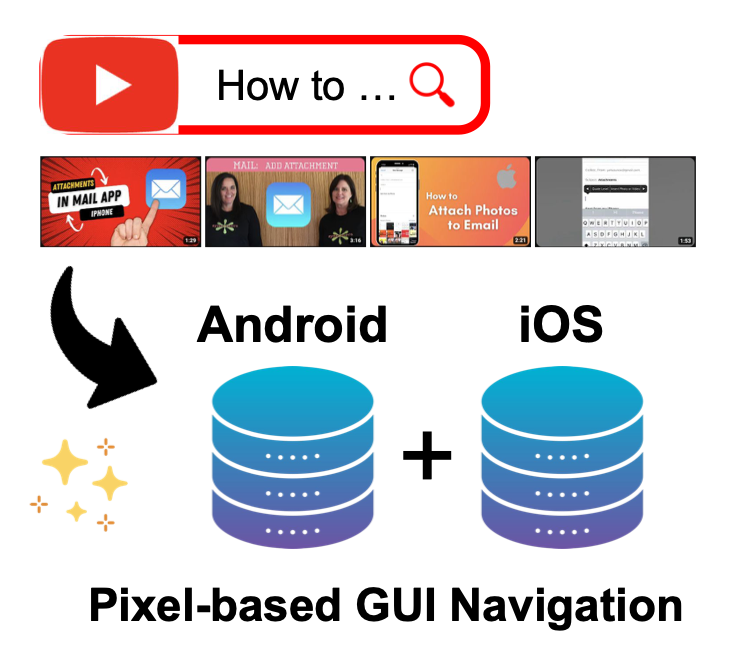
Yunseok Jang*, CVPR, 2025 CVPR Workshop on What is Next in Multimodal Foundation Models?, 2025 CODE / arXiv / Data / Project We introduce the MONDAY, a large-scale dataset of 313K annotated frames from 20K instructional videos capturing diverse real-world mobile OS navigation across multiple platforms. Models that include MONDAY in their pretraining phases demonstrate robust cross-platform generalization capabilities. |
|
|
Yunseok Jang*, NeurIPS Workshop on Video-Language Models, 2024 Non-Archival We introduce MOTIFY, a method for predicting scene transitions and actions from mobile operating system (OS) task videos. It extracts task sequences from YouTube videos without manual annotation, outperforming baselines on Android and iOS tasks and enabling scalable mobile agent development. |
|
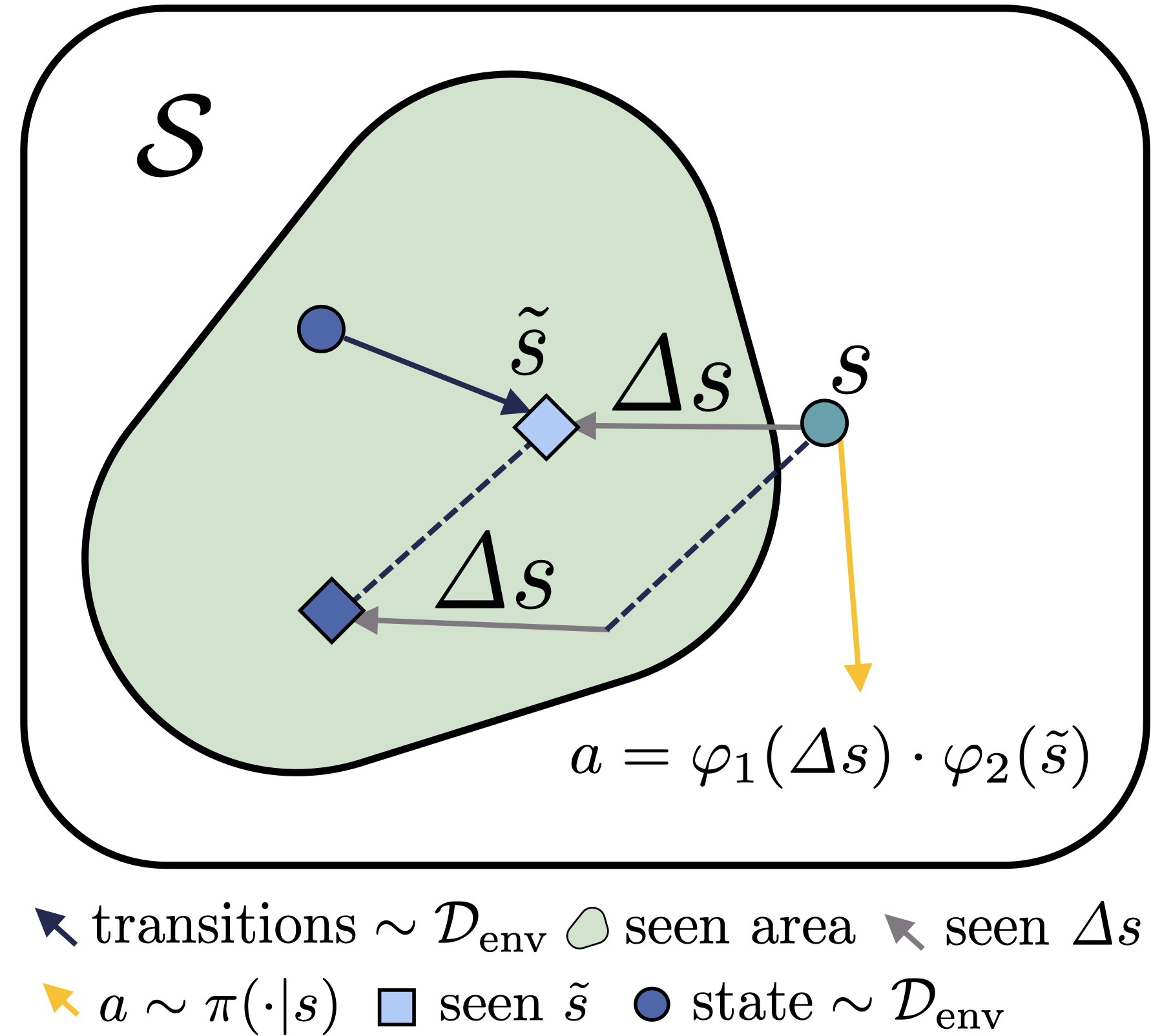
ICLR, 2024 CODE / arXiv We propose COCOA, a novel approach for addressing distributional shifts in offline RL (batch RL). COCOA encourages conservatism within the compositional input space of both the policy and Q-function, independently of the commonly employed behavioral conservatism. |

|
Jaewoo Ahn, ACL, 2023 CODE / arXiv We construct a multimodal persona-grounded dialogue dataset, MPChat, accompanied with entailment labels. The multimodal persona consists of image-text pairs that represent one's episodic memories. We show the role of visual modality is crucial in MPChat through three benchmark tasks. |
|
|
|
Ph.D. student in Computer Science & Engineering |
Aug. 2024 - Current |
|
M.S. in Artificial Intelligence |
Mar. 2022 - Feb. 2024 |
|
B.S. in Statistics B.S. in Artificial Intelligence |
Mar. 2017 - Feb. 2022 |
|
Exchange Student |
Fall 2019 |
|
|
Mar. 2014 - Feb. 2017 |
|
|
|
Research Intern |
Jul. 2025 - Current |
|
Machine Learning Researcher |
Jun. 2021 - Aug. 2021 |
|
Research Intern |
Mar. 2021 - Jun. 2021 |
|
Research Intern |
Jan. 2020 - Jun. 2020 |
|
|
|
|
Dec. 2024 |
|
|
Mar. 2022 - Feb. 2024 |
|
|
Mar. 2017 - Feb. 2021 |
|
|
Mar. 2017 - Jun. 2017 |
|
|
Mar. 2015 - Feb. 2017 |
|
This website is built with Jon Barron's template. |